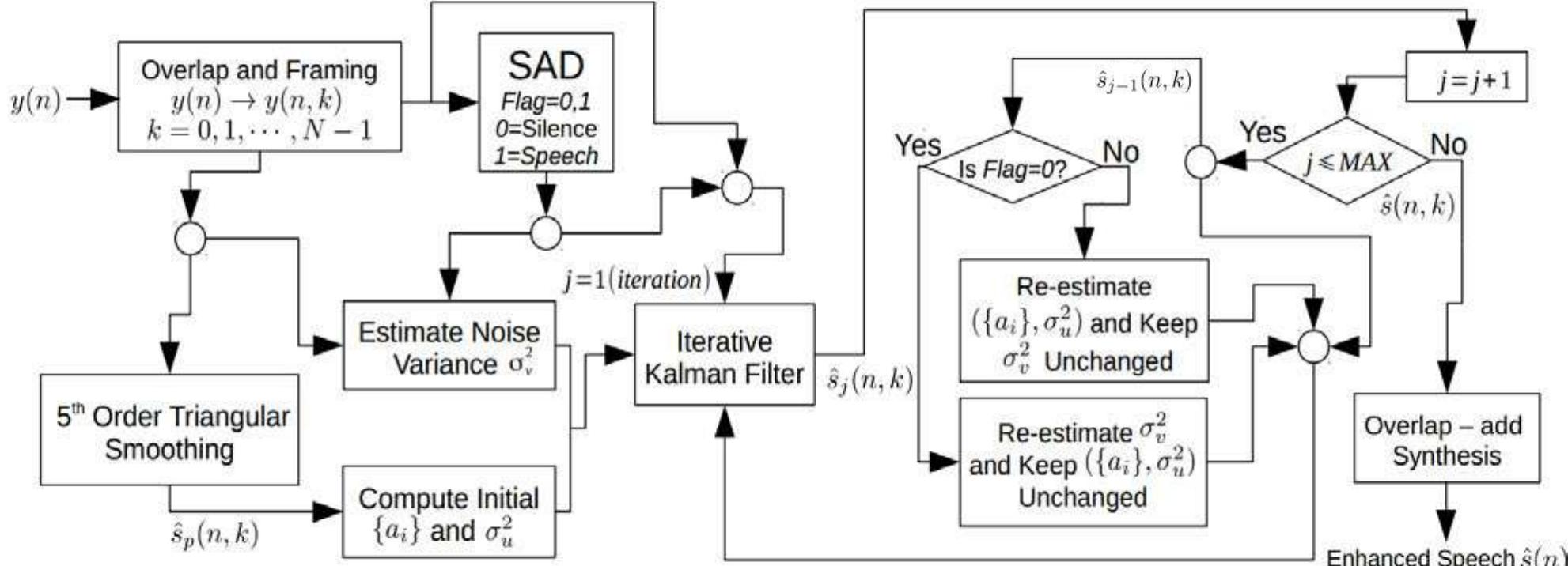
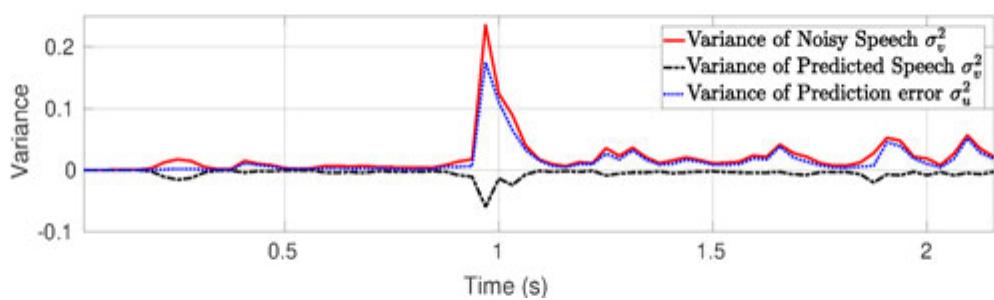
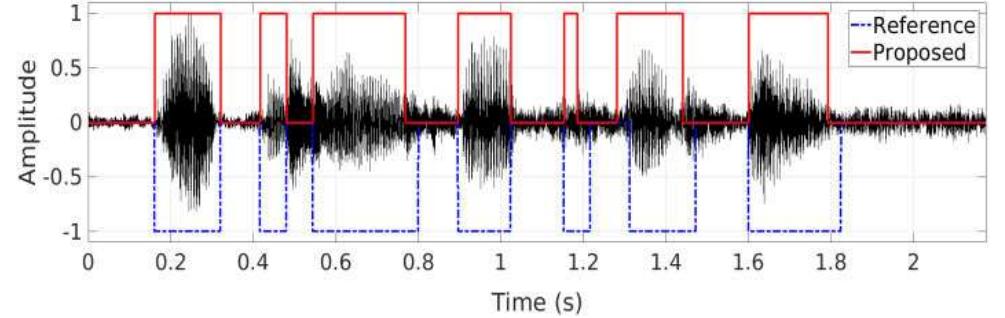
Figure 6 - from "Kalman Filtering with Machine Learning Methods for Speech Enhancement"
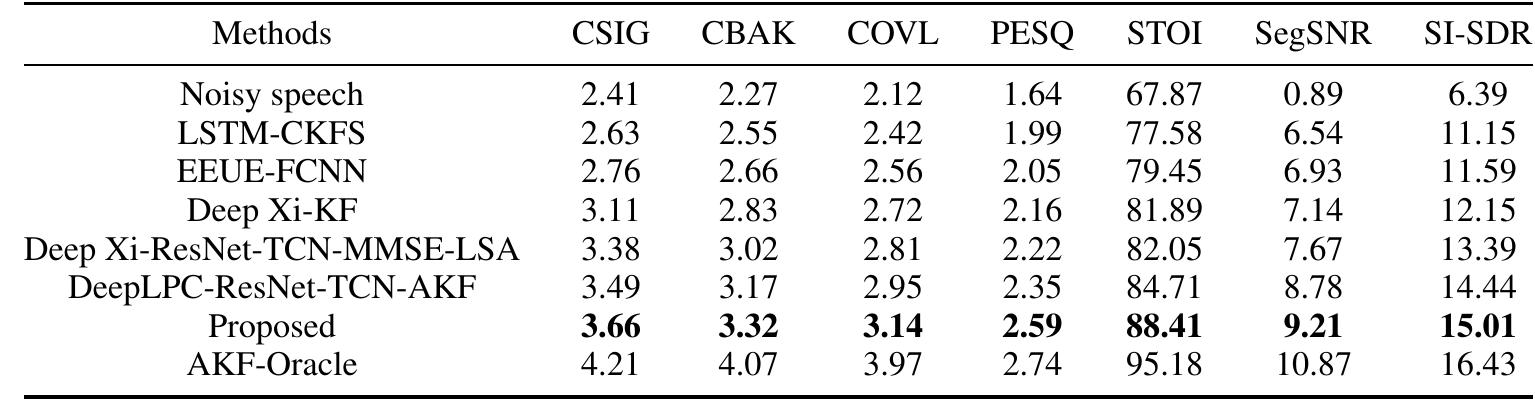
TABLE 3: Mean objective scores on the NOIZEUS dataset in terms of CSIG, CBAK, COVL, PESQ, STOI, SegSNR, and SI-SDR. Apart from AKF-Oracle, the highest score amongst the methods for each measure is given in boldface.
Figure source:
![Figure 1. The impact of 0,2 anda? on biased K 9(n) of NIT-KF: (a) spectrogram of clean speech, (b) spectrogram of noisy speech (corrupted by 0 dB restaurant noise), (c) K9(n), where a2 and 2 are computed in oracle case, (d) spectrogram of enhanced speech (oracle case, PESQ=2.42), (e) K o(n), where o,? and a? are computed from noisy speech, (f) spectrogram of enhanced speech (noisy case, PESQ=2.07). The estimated speech at time n is given by §$(n) = dxX(n|n). The above procedure is repeated for the following frames, yielding the enhanced speech $(n). The clean speech s(n) in eq. (1) can be represented with a p“” order LPCs (a,’s) as [10] Gibson et al. introduced an IT-KF by repeating eqs. (5)-(9) iteratively, where ¥ is formed with the p‘” and q‘" order LPCs of s(n) and v(n). The parameters are re- estimated at the end of each iteration leading to increases the computational complexity. To make computationally efficient, Roy et al. showed that the Y of IT-KF can be formed with the LPCs of s(n) only and effective for non- stationary noise suppression [8]. Unlike the IT-KF in [8], the proposed IT-KF re-estimates the parameters in the subsequent iterations differently based on SAD.](https://figures.academia-assets.com/81742444/figure_001.jpg)
![Figure 4. (a) Noisy speech (corrupted by 0 dB restaurant noise), (b) computed SF, ZCRMS, and KTE from (a). can be predicted through ZCRMS when it rises to 1, while close to 0 for silent frames. Whereas during the speech activity, KTE rises up to 1 and gives a prominent local peak, while goes down to 0 for silent frames [12]. In noisy conditions, Fig. 4 reveals that the SF still varies between 0 to 1 depending on the speech/silent activity. Whereas the ZCRMS and KTE rise up to 1 once the speech activity is present and approaching 0 at silent activity. However, to make the SAD robust against noise, the threshold for each feature continually updated on a framewise basis to implement the corresponding SAD fusions. MV takes the average of SAD fusions € {0,1} (0: silent and 1: speech activity) for each frame and speech activity is present if MV > 0.5, otherwise, silent.](https://figures.academia-assets.com/81742444/figure_004.jpg)
{kind=link}
Abstract: Speech corrupted by background noise (or noisy speech) can reduce the efficiency of communication between man-man and man-machine. A speech enhancement algorithm (SEA) can be used to suppress the embedded background noise and increase the quality and intelligibility of noisy speech. Many applications, such as speech communication systems, hearing aid devices, and speech recognition systems, typically rely upon speech enhancement algorithms for robustness. This dissertation focuses on single-channel speech enhancement using Kalman filtering with machine learning methods. In Kalman filter (KF)-based speech enhancement, each clean speech frame is represented by an auto-regressive (AR) process, whose parameters comprise the linear prediction coefficients (LPCs) and prediction error variance. The LPC parameters and the additive noise variance are used to form the recursive equations of the KF. In augmented KF (AKF), both the clean speech and additive noise LPC parameters are incorporated...